Data Lake, Data Analytics und Data Science unterstützt durch SEEBURGER BIS
| | IT Business Integration, ams OSRAM Group

Bereits seit einigen Jahren sind Themen wie Data Lake und die darauf aufbauende Data Analytics und Data Science ein Dauer-Brenner in vielen IT-Abteilungen.
Der Data Lake bildet hierbei die Grundlage für alle Themen rund um Data Analytics und Data Science. Ein Data Lake wird jedoch erst dann zu einem „Datensee“, wenn er einen „Datenzufluss“ mit Daten aus den Datenquellen hat.
Was ist ein Data Lake?
In einem Data Lake werden möglichst umfangreiche und ungefilterte Rohdaten aus verschiedenen Quellen an zentraler Stelle zur Nutzung bereitgestellt. Das Extrahieren von Daten aus einem Quellsystem und Schreiben in einen Data Lake nennt sich dann Data Ingestion. Im Vergleich zu einem Data Warehouse werden die Daten in einem Data Lake nicht starr nach einem vorab definierten Datenmodell abgelegt. Ziel ist es, Daten zu sammeln, um später zu jeder Zeit beliebige Auswertungen über diese Daten durchführen und daraus neue Erkenntnisse gewinnen zu können, ohne vorab weitere Daten laden zu müssen.
Wie können Daten aus Quellsystemen mit der Business Integration Suite ausgelesen werden?
Die Business Integration Suite bietet eine Vielzahl an Adaptern, Konnektoren und Lösungen, mit denen Daten aus Quellsystemen ausgelesen werden können.
Ist der BIS bereits für Schnittstellen-Aktivitäten im Einsatz, können die folgenden Punkte auch für neue Anwendungsfälle rund um „Data Lake, Data Analytics und Data Science“ genutzt werden:
- Wissen + Erfahrung
- Infrastruktur
- Systeme + Anwendungen
- Prozesse + Lösungen
- Adapter bzw. Konnektoren inklusive Konfiguration (z.B. RFC Client mit einer Anbindung an SAP)
Dadurch werden Aufwände und Redundanzen reduziert und die Transparenz verbessert.
Die Daten werden wahlweise durch das erzeugende System an den BIS übertragen oder durch den BIS zeitgesteuert abgeholt.

Die Liste der Beispiele für Adapter und Konnektoren lässt sich hier beliebig fortführen und entspricht den Anwendungsfällen in dem jeweiligen Unternehmen, das den BIS einsetzt.
Wie kann das Dateiformat harmonisiert werden?
Anders als z.B. bei SQL Datenbanken muss das Ablegen von Daten keinem strikten Datenmodell folgen. Dennoch kann es sinnvoll sein, Daten aus unterschiedlichen Quellen zu harmonisieren, um die spätere Auswertung zu vereinfachen.
Hier bietet sich eine Konvertierung in ein Dateiformat an, das dem Data Lake bereits bekannt ist. Avro und Parquet sind spezielle für Data Lakes geschaffene Datenformate, die Daten besonders effizient und platzsparend abbilden.
Mit dem neuen SEEBURGER BIS Mapping Designer kann eine Konvertierung in das Dateiformat Avro erfolgen. Hier kann sogar ohne starres Schema gearbeitet werden, was die Wiederverwendbarkeit von Mappings ermöglicht. So können beispielsweise verschieden Objekte aus einem Quellsystem über das gleiche Mapping konvertiert werden, wodurch der Aufwand deutlich reduziert wird.
Wie können Daten in den Data Lake geschrieben werden?
Hier kann der SEEBURGER BIS HDFS-Adapter (Hadoop Distributed File System) zum Einsatz kommen. Dieser bietet folgende Optionen im Zusammenhang mit dem Data Lake:
- Autorisierung gegenüber dem Data Lake
- Benutzername und Kennwort
- OAuth 2.0
- Azure Access Key
- Lesen, Schreiben oder Löschen von Dateien
- Abrufen der Dateiliste
- Konsolidierung mehrerer Dateien im Dateiformat Avro zu einer Datei
- Generische Transformation vom Dateiformat Avro nach Parquet
Die Optionen des Adapters bieten umfangreiche Möglichkeiten – per Konfiguration einstellbar. Beispielsweise Data Ingestion in selbst betriebene Data Lakes oder auch in Public Clouds, z.B. in Microsoft Azure Cloud.
Der Adapter ermöglicht zum einen das Bereitstellen einzelner Datenpakete im Data Lake in einem Prozess, zum anderen aber auch die Aufteilung einer großen und lange laufenden Verarbeitung in mehrere kleine und parallel laufende Prozesse mit anschließender Konsolidierung der Datenpakete auf dem Data Lake. Eine Transformation von Avro nach Parquet kann automatisch und ohne Mappingaufwand erfolgen.
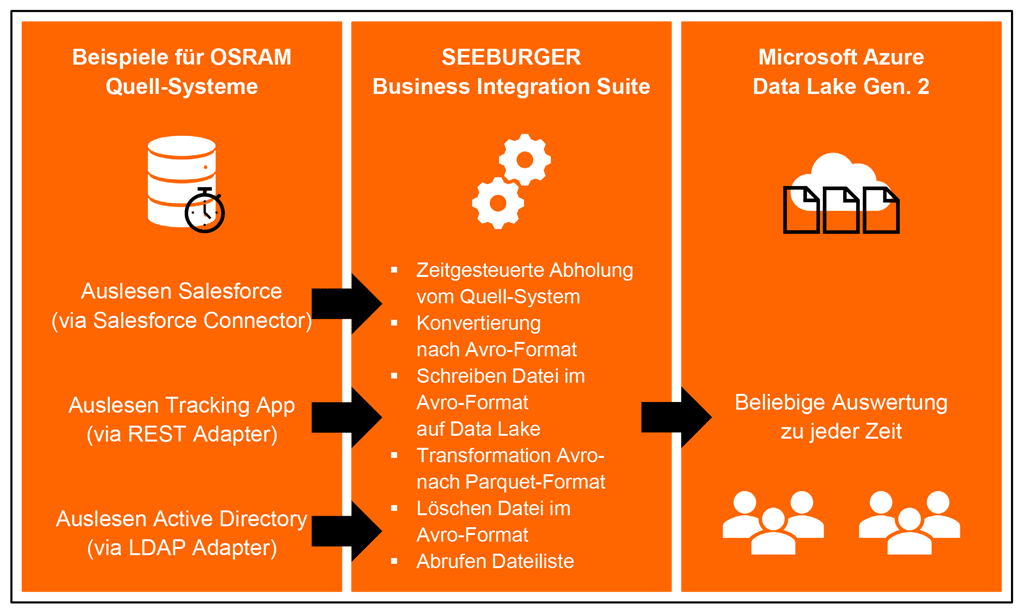
Salesforce, eine Tracking App und das Active Directory sind bei OSRAM derzeit die Datenquellen, deren Daten über den BIS in den Microsoft Azure Data Lake Gen. 2 gelangen.
Dies ermöglicht den Anwendern individuelle Auswertungsmöglichkeiten, beispielsweise über Microsoft Power BI.
Fazit
Die SEEBURGER Business Integration Suite unterstützt auch Anwendungsfälle der Data Lake Integration (Data Ingestion). Der modulare Aufbau der SEEBURGER Suite macht es jedem BIS Anwender auf einfachem Wege möglich, die dazu nötigen Adapter oder Konnektoren nachzurüsten. Durch die Wiederverwertbarkeit von vorhandenen Bestandteilen können Vorlaufzeiten und Aufwände reduziert werden.
Vielen Dank für Ihre Nachricht
Wir freuen uns über Ihr Interesse an SEEBURGER
Haben Sie Fragen oder Anmerkungen?
Wir freuen uns hier über Ihre Nachricht.


Ein Beitrag von: Oliver Rupprecht
Oliver Rupprecht arbeitet seit 1995 für OSRAM und befasst sich seit 2001 mit Business Integration und dem digitalen Wandel. Er ist verantwortlich für die globale Integrationsplattform bei ams OSRAM und unterstützt bei Beratung, Konzeption und Umsetzung von Integrations-Anforderungen.