Data Lake, Data Analytics and Data Science supported by SEEBURGER BIS
| | IT Business Integration, ams OSRAM Group

For some years now, Data Lake and its close cousins Data Analytics and Data Science have been buzzwords in many IT departments.
The Data Lake forms the basis for any topic around Data Analytics and Data Science. However, you can only grow a Data Lake if you also have a data inflow carrying data from its many data sources into it.
What is a Data Lake?
A Data Lake is a reservoir for a wide range of unfiltered raw data from a variety of sources, where it stays until you need to use it. Extracting the data from a source system and writing it into the Data Lake is known as Data Ingestion. Compared to a Data Warehouse, data is not stored according to a strict, predefined data model. The goal is to have a mass of data ready to analyse later in any way you need. This enables you to gain new insights without having to load any further data.
How does BIS read data from source systems?
The Business Integration Suite offers a variety of adapters, connectors and solutions to read data from source systems.
If you are already using BIS for interface activities, the following topics can be used as well for new use cases around “Data Lake, Data Analytics and Data Science”:
- Knowledge + Experience
- Infrastructure
- Systems + Applications
- Processes + Solutions
- Adapters resp. connectors including configuration (e.g. an RFC Client linked to SAP)
This not only reduces effort and redundancy, but also increases transparency.
The data can either be transferred to the BIS from the generating system or retrieved by the BIS with a scheduled task.
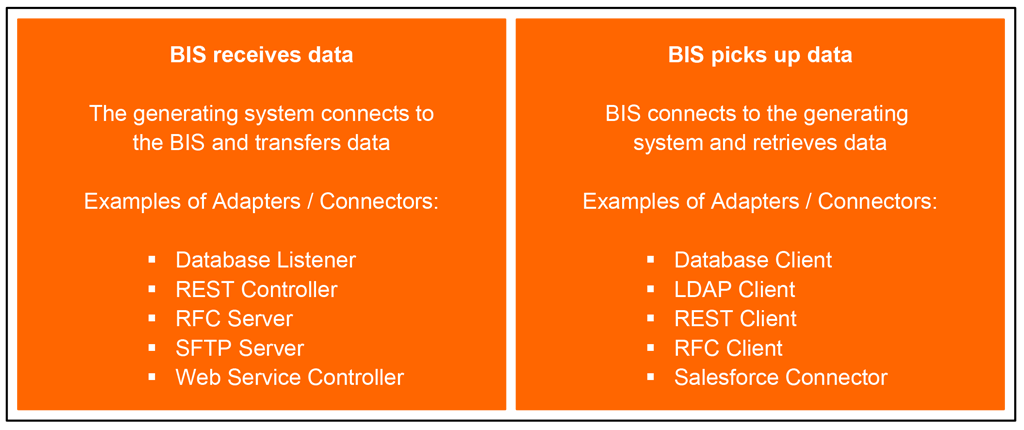
This list of example adapters and connectors can be extended to almost indefinitely, depending on the combinations required in a particular organisation using BIS.
How can you harmonise the data format?
In contrast to e.g. SQL databases, filling the data doesn’t need to follow a strict data model. Nevertheless, it can make sense to harmonise the data from the various sources to make later analysis easier.
A good solution would be to translate the data into a file format already known by the data lake. Avro and Parquet are data formats especially created for Data Lakes to enable data to be stored there efficiently.
The new SEEBURGER BIS Mapping Designer can be used to translate the data into an “Avro” format. You don’t even need to work with a rigid structure, enabling you to reuse the same mappings several times to convert a variety of objects from one source system. This significantly reduces your workload.
How can data be written to the Data Lake?
A good solution would be to use the SEEBURGER BIS HDFS Adapter (Hadoop Distributed File System). This offers the following options for Data Lakes:
- Authorisation for access to Data Lake
- User name and Password
- OAuth 2.0
- Azure Access Key
- Read, write or delete files
- Retrieve the file list
- Merge multiple files in file format Avro into one single file
- Generic transformation from file format Avro to Parquet
The options of the adapter can be easily configured to give you extensive possibilities. Data can be ingested into Data Lakes operated on-premise, or into public clouds such as Microsoft Azure Cloud.
The adapter could place single data packages into the Data Lake in one process or could divide larger and longer-running processes into smaller, parallel running processes and merge the data packages later in the Data Lake. A transformation from Avro to Parquet can be done automatically and without mapping effort.
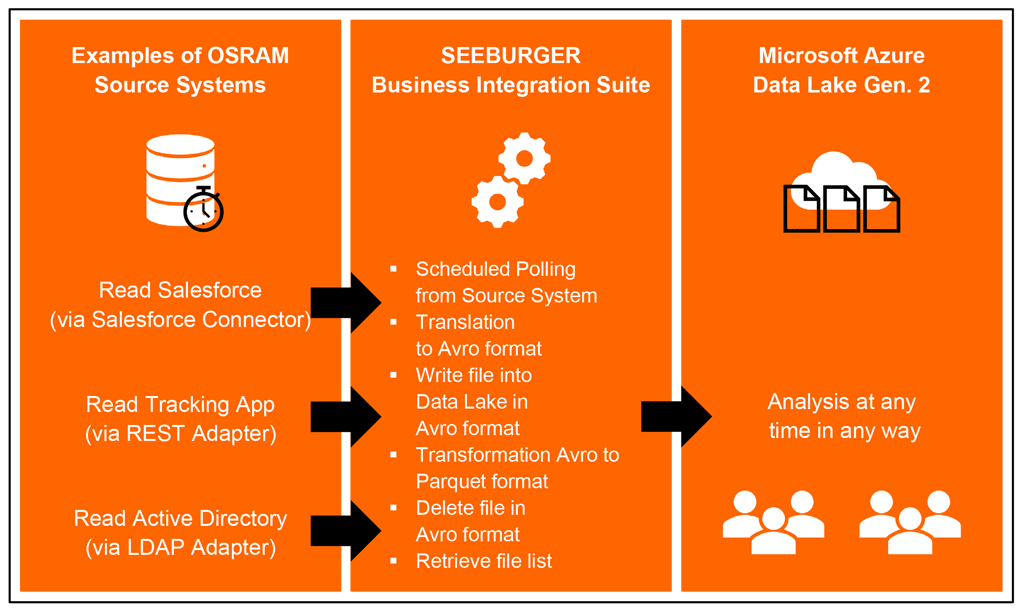
Salesforce, a Tracking App and the Active Directory are currently the data sources, whose data is transferred to Microsoft Azure Data Lake Gen. 2 via the BIS.
This allows the users individual possibilities for analysis, for example via Microsoft Power BI.
Conclusion
The SEEBURGER Business Integration Suite also supports a Data Lake and Data Ingestion. The modular structure of the SEEBURGER Suite makes it easy for BIS users to add the required adapters. With the option to reuse existing components, lead times and effort can be reduced.
Thank you for your message
We appreciate your interest in SEEBURGER
Get in contact with us:
Please enter details about your project in the message section so we can direct your inquiry to the right consultant.


Written by: Oliver Rupprecht
Oliver Rupprecht works for OSRAM since 1995 and deals with Business Integration and the digital change since 2001. He is responsible for the global integration platform at ams OSRAM and supports on consulting, conception and realization of integration demands.